

Благодаря новым алгоритмам и достижениям ИТ машины теперь могут изучать все более сложные модели. Они приходят для создания высококачественных синтетических данных, таких как фотореалистичные изображения и даже резюме воображаемых людей.
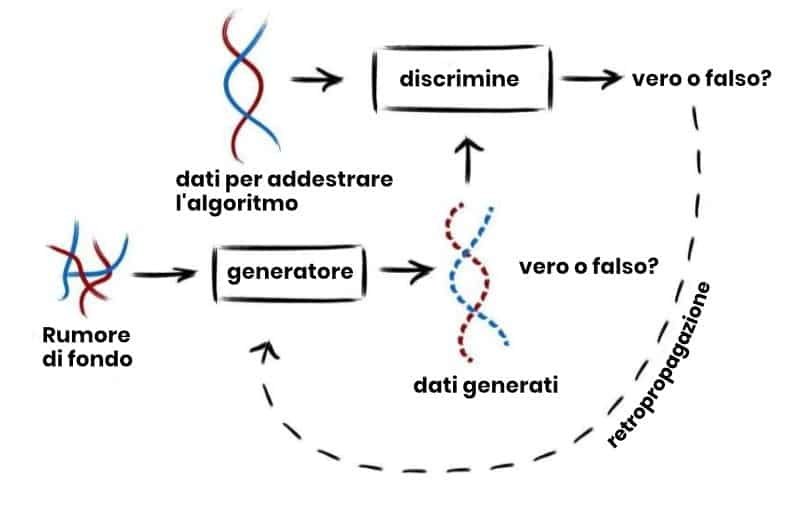
Ora исследование, опубликованное в международном журнале PLoS Genetics показывает расширенное использование машинного обучения для биометрических данных. Из существующих биобанков система генерирует целые блоки человеческого генома, которые не принадлежат реальному человеку, но имеют характеристики реального генома.
В обход проблемы конфиденциальности
«Существующие геномные базы данных являются бесценным ресурсом для биомедицинские исследования," Он говорит Бурак Ельмен, первый автор исследования и младший научный сотрудник современной популяционной генетики Тартуского университета. «Проблема в том, что они не являются общедоступными и не защищены долгими и затяжными процедурами правоприменения из-за обоснованных этических соображений. Это создает серьезный научный барьер для исследователей. Геном, сгенерированный машиной, «искусственный геном», может помочь нам решить проблему в безопасных этических рамках».
:format(jpg):extract_cover()/https%3A%2F%2Fscx1.b-cdn.net%2Fcsz%2Fnews%2F800a%2F2021%2F13-machinelearn.jpg)
Многопрофильная команда провела несколько анализов, чтобы оценить качество генома, созданного с помощью машинного обучения, по сравнению с реальным. «Примечательно, что этот геном имитирует сложности, которые мы можем наблюдать в реальных человеческих популяциях, и по большинству свойств они неотличимы от других геномов биобанка, используемого для обучения нашего алгоритма. За исключением одной детали: они не принадлежат ни одному генному донору», — сказал он. доктор Лука Пагани, один из главных авторов исследования и сотрудник Mobilitas Pluss.
Геном, сгенерированный машиной, «искусственный геном», может помочь нам решить проблему в безопасных этических рамках.
Бурак Ельмен
Действительно ли геном оригинален или это «вылитая» копия?
Исследование также включает оценку близости искусственного генома к реальному, чтобы проверить, сохраняется ли конфиденциальность исходных образцов. «Хотя обнаружение утечек конфиденциальности в тысячах геномов может показаться поиском иголки в стоге сена, сочетание нескольких статистических показателей позволяет нам тщательно проверять все закономерности. Интересно, что детальное изучение сложных моделей дисперсии, в свою очередь, приводит к другим улучшениям в оценке ГАН и будет способствовать развитию машинного обучения». Доктор говорит это Флора Джей, координатор исследований и научный сотрудник Национального центра научных исследований Франции CNRS).
В общем, подходы машинного обучения уже предоставлены Volti, биографии и многие другие особенности горстке воображаемых людей. Теперь мы знаем больше об их биологии. Эти вымышленные люди с реалистичными геномами могут служить экспериментальным стендом вместо настоящих геномов, которые не являются общедоступными.

